




I. Qu'est-ce que l'énergie ?▲
I-A. Introduction à la problématique de l'énergie▲
Les ordinateurs deviennent de plus en plus puissants et effectuent des calculs de plus en plus rapidement. Toutefois, cette puissance de calcul a un coût. En effet, l'augmentation de la puissance de calcul des machines s'accompagne d'une consommation accrue d'énergie électrique pour délivrer cette puissance. Pour les périphériques mobiles, les utilisateurs le ressentent directement étant donné l'impact sur l'autonomie. Mais ce n'est pas le seul domaine où la problématique de l'énergie est devenue cruciale. En effet, les superordinateurs sont composés de plusieurs milliers de nœuds de calcul (ou processeurs) et consomment tellement d'énergie électrique, qu'il ne sera bientôt plus possible de les alimenter correctement. Par exemple, le Tianhe-2, le superordinateur le plus puissant en 2013 a une consommation de 17 MW équivalant à la consommation d'environ 21 000 habitants français. Afin de continuer à produire des superordinateurs plus puissants, il devient donc essentiel de réduire leur consommation électrique.
I-B. Qu'est-ce que la puissance ? L'énergie ?▲
Deux métriques sont couramment utilisées pour qualifier la performance énergétique des programmes. La première est la puissance, la seconde : l'énergie. Ces deux métriques représentent deux choses distinctes, mais liées. La notion la plus simple à comprendre est l'énergie. Elle correspond grossièrement à la quantité d'énergie à fournir à l'ordinateur pour qu'il puisse réaliser le calcul qu'on lui demande. Plus le calcul sera long et complexe, plus la quantité d'énergie nécessaire pour réaliser ce calcul est importante. La puissance peut être vue comme une consommation énergétique instantanée. Celle-ci ne dépend pas de la quantité (ou longueur) du calcul. Pour bien comprendre, on peut considérer une analogie avec un trajet en voiture. Notre voiture consomme une certaine quantité d'essence, c'est-à-dire d'énergie. Plus nous roulons vite et plus nous roulons longtemps, plus il faudra d'essence. Dans cette analogie, la puissance est équivalente à la consommation instantanée. Cette consommation instantanée ne dépend pas de la durée du parcours, mais plutôt de notre vitesse : plus on roule vite, plus la consommation instantanée sera importante. La consommation instantanée est liée à la quantité d'essence : la quantité d'essence consommée correspond à la consommation moyenne sur le trajet multipliée par le temps de parcours. De la même façon, puissance et énergie sont liées : l'énergie est égale à la puissance moyenne multipliée par le temps, ou plus exactement à l'intégrale de la puissance par le temps.
On exprime souvent la puissance en watts (W) et l'énergie en joules (J) ou kilowatt-heure (kWh). Un joule correspond à un watt-seconde, c'est-à-dire à la consommation d'un watt pendant une seconde. Le kilowatt-heure correspond, comme son nom l'indique, à la consommation de mille watts pendant une heure. On a donc l'équivalence suivante : 1 kWh = 3 600 000 J.
Mathématiquement, on exprime l'énergie en utilisant la formule suivante (on utilise couramment « e » pour noter l'énergie et « P » pour la puissance) :
kitxmlcodelatexdvpe = \int_t(P)finkitxmlcodelatexdvp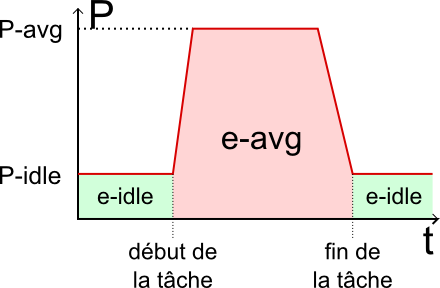
On peut voir sur le schéma la puissance consommée par l'exécution d'un programme. Lorsque le programme n'est pas encore démarré ou après qu'il a fini, la puissance consommée est relativement faible. On appelle P-idle cette puissance. Elle correspond à la puissance nécessaire pour maintenir l'ordinateur allumé. Lorsque le programme s'exécute, on voit sur le schéma que la puissance consommée est plus importante. En effet, l'ordinateur a besoin de plus d'électricité pour pouvoir faire les calculs demandés. On appelle P-avg la puissance moyenne nécessaire à l'exécution du programme.
Nous n'avons pas encore parlé de l'énergie nécessaire à l'exécution du programme. En réalité l'énergie nécessaire à l'exécution du programme est égale à l'intégrale de P-avg sur le temps d'exécution du programme, c'est-à-dire ici P-avg multipliée par le temps d'exécution.
Une fois ces notions maîtrisées, on peut envisager réduire cette énergie. Différentes techniques sont présentées par la suite pour réduire la consommation énergétique.
I-C. Mesures d'énergie▲
Avant de considérer les optimisations énergétiques, il est important de savoir comment mesurer la consommation d'un ordinateur ou d'un processeur. Pour mesurer l'énergie à l'échelle d'un ordinateur, il faut généralement brancher un wattmètre à l'ordinateur. Il s'agit d'un outil de mesure qui sert justement à mesurer la puissance consommée. Cette solution est précise, car elle permet de savoir combien consomme un ordinateur complet, mais elle est également chère et complexe.
Lorsque cela est suffisant, il est aussi possible de mesurer l'énergie consommée par le processeur grâce à des sondes d'énergie introduites récemment sur les processeurs Intel (à partir de la génération SandyBridge). Donc si vous possédez un tel processeur, vous pourrez facilement surveiller l'énergie et la puissance consommées par votre processeur.
I-C-1. Model-Specific Register▲
Les « Model-Specific Register » (MSR) (page de manuel des MSR) sont des registres spécifiques notamment utilisés dans le débogage et l'analyse des applications. Depuis la génération SandyBridge, les processeurs Intel possèdent des registres particuliers (technologie RAPL), qui contiennent la puissance consommée par le processeur.
Sous Linux, ces registres sont disponibles via /dev/cpu/N/msr où N est le numéro du cœur à observer.

|
Il est souvent nécessaire de lire la documentation des constructeurs de CPU afin de connaître les registres exacts à utiliser. |
L'exemple ci-dessousExemple propose un code C simple permettant de lire les informations sur l'énergie.
I-C-2. Intel Energy Checker SDK▲
Intel propose avec « Intel Energy Checker SDK » un ensemble d'outils permettant d'obtenir de nombreuses informations liées à l'énergie sur un programme ou sur des portions précises d'un code. Pour ce faire, Intel propose une bibliothèque à intégrer à son projet vous permettant de sélectionner les sondes à observer et d'en extraire des informations utiles. De plus, le SDK inclut un outil similaire à la commande time sous Linux pour mesurer facilement la consommation énergétique.
N'hésitez pas à consulter le document « SDK User Guide » (en anglais) pour voir comment se servir de l'outil. Le document contient également quelques exemples d'optimisations énergétiques.
I-D. Réduction de e-idle▲
Plusieurs solutions existent pour réduire e-idle. En effet, comme cette consommation énergétique a lieu par le simple fait que la machine soit allumée (sans travailler), il est théoriquement possible de l'arrêter tant qu'elle n'est pas utilisée pour du calcul.
I-D-1. S-states▲
Les S-states sont un ensemble d'états (hibernation, extinction…) pendant lesquels la machine est arrêtée progressivement. Par exemple, si la machine n'a pas été utilisée pendant dix minutes, elle hibernera. Si la machine n'est toujours pas utilisée pendant cinquante autres minutes, elle s'éteindra. Bien sûr, si la machine doit effectuer un calcul, elle devra être rallumée.
Cette méthode possède un désagrément, car la sortie d'hibernation, ou le redémarrage de la machine prendra du temps et consommera de l'énergie sans pour autant effectuer de calcul. Toutefois, ce coût est compensé si la machine est éteinte assez longtemps.
I-D-2. C-states▲
Les C-states reprennent le principe des S-states mais à une plus petite échelle. En effet, les C-states se limitent à arrêter des parties du CPU lorsque celui-ci est inutilisé, entraînant une diminution de la consommation énergétique. Les modules sont réveillés lors des interruptions matérielles (souris, réseau…). Contrairement aux S-states, les temps d'inactivité pour arrêter progressivement le CPU se comptent en centaines de millisecondes et non plus en minutes.
Plus la machine est profondément endormie, que ce soit pour le CPU, ou l'ensemble de la machine, plus le coût du réveil est important.
I-E. Réduction de e-avg▲
La réduction de e-avg est généralement plus difficile à obtenir que celle de e-idle. En effet, cette fois, la réduction de la consommation énergétique doit se faire alors qu'un programme est en cours d'exécution. Étant donné que l'énergie est égale à la puissance fois le temps d'exécution, nous avons deux possibilités : réduire le temps d'exécution ou réduire la puissance consommée. Il faut par contre être très prudent et s'assurer que par exemple une diminution de la puissance ne provoque pas une augmentation trop importante du temps d'exécution.
I-E-1. Réduction du temps d'exécution▲
Pour réduire le temps d'exécution, il faut optimiser le programme. La première étape sera donc de profiler le programme pour connaître les parties les plus gourmandes en temps de calcul, puis de les améliorer en utilisant les techniques habituelles d'optimisation.
I-E-2. Réduction de la puissance▲
Les nouvelles générations de processeur permettent de changer la fréquence à la volée. Cette technologie s'appelle « Dynamic Voltage and Frequency Scaling » (DVFS) et permet de changer la fréquence et la tension du processeur, ce qui réduira sa consommation, mais aussi, sa puissance de calcul et donc ralentira les programmes.
II. Dynamic Voltage and Frequency Scaling▲
Le « Dynamic Voltage and Frequency Scaling » permet de réduire (ou d'augmenter) la fréquence du CPU influençant ainsi sur la consommation énergétique, tout en ayant un impact sur le temps d'exécution. La puissance est liée à la fréquence et ce lien peut être simplifié par la formule suivante :
kitxmlcodelatexdvpP \approx \alpha f^3 + \betafinkitxmlcodelatexdvpLe temps dépend également de la fréquence, mais cela n'est pas linéaire. Cela dépendra du travail effectué par le CPU, il est donc nécessaire d'analyser les programmes exécutés.
II-A. Caractérisation des programmes▲
Les programmes sont tous différents et chaque programme peut réagir différemment à un changement de fréquence. Cependant, on distingue généralement deux comportements extrêmes : les programmes intensifs en calculs (CPU bound) et, à l'opposé, ceux avec beaucoup d'accès mémoire (memory bound). Selon la quantité de calculs (et d'accès mémoire), un programme peut donc être plus ou moins CPU bound (et inversement, plus ou moins memory bound).
II-A-1. CPU Bound▲
Lorsque le programme contient beaucoup de calculs et très peu d'accès mémoire, le CPU doit fonctionner à pleine puissance et calculer aussi vite que possible. C'est le cas dit « CPU bound ». Dans ce cas, il faut augmenter autant que possible la fréquence pour finir au plus vite le calcul ; si la fréquence est diminuée, le programme ralentira fortement.
Si la fréquence est diminuée, le temps de calcul augmentera et donc l'énergie consommée risque d'être plus importante.
II-A-2. Memory Bound▲
Dans d'autres cas, le CPU a besoin de beaucoup de données en RAM pour effectuer peu de calculs. Il faut alors remarquer que la mémoire vive est très lente par rapport au CPU et que dans la plupart des cas, le CPU ne peut pas continuer ses calculs avant que les données n'arrivent. Dans ce cas, il n'est pas nécessaire que le CPU aille plus vite que la mémoire et on peut diminuer la fréquence CPU sans impacter fortement le temps d'exécution.
Si la fréquence est diminuée, le temps de calcul n'augmentera presque pas et la consommation énergétique pourra être diminuée.
II-A-3. Exemple▲
Vous pouvez télécharger un exemple simple démontrant cela. Le programme ne fait que les choses suivantes :
- utiliser la fréquence passée en argument par l'utilisateur ;
- prendre une mesure ;
- effectuer le test (travail intensif multithread soit sur la mémoire (bench_memory), soit sur le CPU (bench_cpu)) ;
- prendre une seconde mesure ;
- afficher la différence entre les deux mesures d'énergie.
II-A-3-a. Résultats▲
Ces tests ont été effectués sur une machine composée d'un : Intel(R) Core(TM) i7-3770 CPU, avec 16 Go de RAM, sous GNU/Linux 3.8.8. La fréquence minimale est de 1,6 GHz et la fréquence maximale de 3,4 GHz.
| Fréquence | Temps d'exécution (en secondes) | Énergie (en joules) | Puissance (en watts) | |
| bench_cpu (« cpu bound ») |
1,6 Ghz | 38,2 | 485,8 | 12,6 |
| 3,4 Ghz | 17,4 | 494,3 | 28,2 | |
| bench_memory (« memory bound ») |
1,6 Ghz | 19,9 | 309,5 | 15,4 |
| 3,4 Ghz | 14,2 | 443,5 | 31,0 |
En réalité, ce processeur possède une fréquence signalée à 3,401 GHz, correspondant à la fréquence de la technologie « TurboBoost » d'Intel. Elle donne certes un boost aux applications, mais est généralement très coûteuse en termes d'énergie.
Un bon choix de fréquence nécessite une parfaite connaissance de l'ordinateur et de son programme. C'est pour cela qu'on laisse généralement les outils automatiques choisir la meilleure fréquence à tout moment.
II-B. Contrôle de la fréquence du CPU▲
II-B-1. Outils manuels▲
Il est possible de changer la fréquence du CPU directement depuis le système d'exploitation. Sous Linux, le pilote pour le faire est cpufreq.Il vous permettra d'accéder aux informations de fréquence et aux gouverneurs (politique de changement automatique des fréquences) à travers les fichiers situés dans /sys/devices/system/cpu/cpuX/cpufreq(où X est le numéro du cœur).
II-B-1-a. cpufreq▲
cpufreq est un pilote Linux pour le CPU. Il donne la possibilité de configurer la fréquence à la volée à travers une série de fichiers, ainsi que de définir une politique de sélection automatique de fréquence. Les politiques de choix de fréquence sont appelées « gouverneurs » et, en général on utilise principalement les gouverneurs « ondemand » pour un choix automatique de la fréquence et « userspace » pour définir les fréquences manuellement.
Depuis les noyaux 3.9, cpufreq n'est plus le pilote par défaut pour contrôler la fréquence processeur avec les processeurs Intel. Le pilote cpufreq n'a cependant pas disparu, il faut simplement l'activer au démarrage du noyau.
Voici les fichiers accessibles à travers cpufreq et leur utilité.
| /sys/devices/system/cpu/cpuX/cpufreq/cpuinfo_cur_freq | Fréquence actuellement utilisée, telle qu'indiquée par le matériel (en kHz). |
| /sys/devices/system/cpu/cpuX/cpufreq/scaling_available_frequencies | Liste des fréquences disponibles (en kHz). |
| /sys/devices/system/cpu/cpuX/cpufreq/scaling_available_governors | Liste des gouverneurs disponibles. |
| /sys/devices/system/cpu/cpuX/cpufreq/scaling_cur_freq | Fréquence actuellement utilisée, telle qu'indiquée par le gouverneur (en kHz). Cette vitesse et celle à laquelle le kernel pense que le CPU est, mais peut être différente de la réalité. |
| /sys/devices/system/cpu/cpuX/cpufreq/scaling_governor | Actuel gouverneur en fonctionnement. Si vous écrivez une autre valeur dans ce fichier, cela provoquera le changement du gouverneur. |
| /sys/devices/system/cpu/cpuX/cpufreq/scaling_setspeed | Si vous avez sélectionné le gouverneur « userspace », vous pouvez écrire dans ce fichier la fréquence à laquelle vous voulez que votre cœur fonctionne. |
Pour un contrôle entièrement manuel, il suffit d'écrire « userspace » dans le fichier /sys/devices/system/cpu/cpuX/cpufreq/scaling_governor et la fréquence voulue dans /sys/devices/system/cpu/cpuX/cpufreq/scaling_setspeed parmi la liste des fréquences disponibles dans /sys/devices/system/cpu/cpuX/cpufreq/scaling_available_frequencies.
II-B-1-b. Libdvfs▲
Le projet libDVFS, hébergé sur Google Code, vous permet de contrôler le DVFS de votre CPU sous Linux à partir d'une bibliothèque C. La bibliothèque utilise les fichiers de cpufreq pour ce faire.
II-B-2. Outils automatiques▲
Des outils existent afin de permettre un meilleur contrôle de la fréquence du CPU suivant son utilisation de celui-ci. Grâce à ces outils, la machine s'autorégule et permet généralement d'économiser de l'énergie.
Linux utilise un gouverneur par défaut « ondemand » pour cpufreq. Celui-ci choisit la fréquence minimale, lorsque le CPU n'est pas utilisé et la fréquence maximale dès qu'une activité est détectée. Ce comportement simple donne généralement de bons résultats, mais n'est pas toujours optimal (il ne tient par exemple pas compte de la nature CPU bound ou Memory bound des programmes).
III. Autres solutions▲
Le DVFS est certes une première solution pour économiser de l'énergie, mais elle n'est pas la seule. La seconde grande idée est d'optimiser l'utilisation des machines. En effet, si un programme n'utilise que 50 % du CPU, les 50 % restant sont gâchés et auraient pu être utilisés pour faire fonctionner un second programme en parallèle par exemple.
III-A. Dynamic Concurrency Throttling▲
Le « Dynamic Concurrency Throttling » (DCT) est une technique d'économie d'énergie basée sur le nombre de cœurs à utiliser pour chaque région parallèle. En effet, l'exécution d'un calcul en parallèle réduit le temps de calcul, mais le gain n'est pas linéaire par rapport au nombre de cœurs utilisés. Chaque cœur supplémentaire consommera un supplément d'énergie. Lorsque l'accélération devient trop faible, il peut être intéressant d'utiliser moins de cœurs afin de limiter la consommation énergétique.
III-B. Consolidation de serveur▲
Les problèmes d'énergie touchent aussi les fermes de serveur, en particulier pour les sites web. Les sites web sont souvent hébergés dans des machines virtuelles permettant de faire fonctionner plusieurs machines virtuelles sur une machine physique. La consolidation de serveur consiste à optimiser le placement des machines virtuelles afin d'utiliser au maximum les machines physiques (efficacité augmentée) et aussi d'utiliser moins de machines physiques (extinction des machines non utilisées).
IV. Étude de cas▲
Afin de mettre en pratique ce que nous venons de voir, nous allons nous intéresser à un programme OpenMP simple et observer l'impact des modifications effectuées sur l'énergie et le temps d'exécution.
Les tests ont été effectués sur une machine composée d'un : Intel(R) Core(TM) i7-3770 CPU, avec 16 Go de RAM, sous GNU/Linux 3.8.8. La fréquence minimale est de 1,6 GHz et la fréquence maximale de 3,4 GHz. Par défaut, OpenMP utilise les huit threads.
IV-A. Programme initial▲
Ce programme initial utilise OpenMP pour incrémenter un compteur en parallèle. Voici le code :
#include <stdio.h>
#include <unistd.h>
#include <math.h>
#include <omp.h>
#include "probe_time.h"
#include "probe_msr.h"
#define COUNTER 50000000
int main(int argc, char** argv)
{
int msrFD = 0;
double startPower=0;
double endPower=0;
long long unsigned startTime=0;
long long unsigned endTime=0;
msrFD = open_msr(0);
if ( msrFD < 0 )
{
fprintf(stderr,"Fail to init MSR probe\n");
return -1;
}
// Première mesure
startTime = getTime();
startPower = readPower(msrFD);
fprintf(stdout,"Threads : %d\n",omp_get_max_threads());
// Test
{
unsigned int n = 0;
unsigned int i = 0;
#pragma omp parallel for private(n)
for (n = 0 ; n < COUNTER ; n++ )
{
#pragma omp critical
{
i+=sqrt(i);
}
}
printf("Result %d\n",i);
}
// Seconde mesure
endPower = readPower(msrFD);
endTime = getTime();
// On affiche la différence entre les deux mesures pour avoir une consommation
printf("Energie : %f (J) | Temps : %llu (ms) | Puissance : %f (W)\n",endPower-startPower,endTime-startTime,(endPower-startPower)/((double)(endTime-startTime)/1000.0));
// Nettoyage
close(msrFD);
return 0;
}Sachant que la section parallélisée utilise une seule variable pour travailler, il est nécessaire de la protéger contre les accès concurrents grâce à #pragma omp critical.
La machine de test nous renvoie ces résultats :
| Fréquence | Temps (en millisecondes) | Puissance (en watts) | Énergie (en joules) |
| 1,6 GHz | 17 927 | 14 | 251,7 |
| 3,4 GHz | 8436 | 28,1 | 236,9 |
Le #pragma omp critical permet de protéger la variable, mais entraîne aussi la mise en attente des threads et l'exécution du test devient séquentielle (un seul thread peut travailler à la fois). Deux optimisations sont alors possibles :
- réduire le temps d'exécution en optimisant la performance du programme ;
- réduire la puissance consommée par le programme en utilisant moins de ressources.
IV-B. Optimisation en performance▲
Pour améliorer la performance du programme, nous pouvons enlever la synchronisation des threads (et donc de la section critique), nous utiliserons une réduction pour cela. OpenMP va transformer la variable 'i' en variable locale au thread et additionnera chaque variable locale des threads à la fin de boucle. Voici le code modifié de la section parallélisée :
{
unsigned int n = 0;
unsigned int i = 0;
#pragma omp parallel for private(n) reduction(+:i)
for (n = 0 ; n < COUNTER ; n++ )
{
i++;
}
fprintf(stdout,"Result %d\n",i);
}Maintenant, les huit threads peuvent s'exécuter en parallèle. Voici les nouveaux résultats :
| Fréquence | Temps (en millisecondes) | Puissance (en watts) | Énergie (en joules) |
| 1,6 GHz | 8 | 14,1 | 0,1 |
| 3,4 GHz | 3,5 | 27 | 0,1 |
IV-C. Optimisation en puissance▲
L'optimisation en puissance consiste à réduire le nombre de threads utilisés. En effet, le programme contient une section critique qui empêche toute exécution parallèle ; on peut donc se contenter de moins de threads pour exécuter notre programme. En utilisant moins de threads, les cœurs inutilisés du processeur pourront alors ralentir et consommer moins d'énergie.
Le code nous permettant cela est le suivant :
{
unsigned int n = 0;
unsigned int i = 0;
#pragma omp parallel for num_threads(nbThreads) private(n)
for (n = 0 ; n < COUNTER ; n++ )
{
#pragma omp critical
{
i++;
}
}
fprintf(stdout,"Result %d\n",i);
}Le nombre de threads à utiliser est passé en argument par la variable nbThreads. Voici les résultats du test :
| Nombre de threads | Fréquence | Temps (en millisecondes) | Puissance (en watts) | Énergie (en joules) |
| 1 | 1,6 GHz | 1819 | 7,8 | 14,2 |
| 3,4 GHz | 855 | 13,1 | 11,2 | |
| 2 | 1,6 GHz | 7351 | 9,8 | 75,4 |
| 3,4 GHz | 3095 | 17,6 | 66,6 | |
| 4 | 1,6 GHz | 11 962 | 13,7 | 164,1 |
| 3,4 GHz | 4435 | 25 | 110,7 | |
| 8 | 1,6 GHz | 18 022 | 14,1 | 253,2 |
| 3,4 GHz | 8413 | 28,2 | 236,9 |
IV-D. Récapitulatif▲
Voici la table récapitulative des résultats de nos trois benches :
| Test | Fréquence | Nombre de threads | Temps (en millisecondes) | Puissance (en watts) | Énergie (en joules) |
| Test originalProgramme initial | 1,6 GHz | 8 | 17 927 | 251,7 | 14 |
| 3,4 GHz | 8436 | 236,9 | 28,1 | ||
| Test optimisé en performanceOptimisation en performance | 1,6 GHz | 8 | 14,1 | 8 | 0,1 |
| 3,4 GHz | 27 | 3,5 | 0,1 | ||
| Test optimisé en puissanceOptimisation en puissance | 1,6 GHz | 1 | 1819 | 7,8 | 14,2 |
| 3,4 GHz | 855 | 13,1 | 11,2 | ||
| 1,6 GHz | 2 | 7351 | 9,8 | 75,4 | |
| 3,4 GHz | 3095 | 17,6 | 66,6 | ||
| 1,6 GHz | 4 | 11 962 | 13,7 | 164,1 | |
| 3,4 GHz | 4435 | 25 | 110,7 | ||
| 1,6 GHz | 8 | 18 022 | 14,1 | 253,2 | |
| 3,4 GHz | 8413 | 28,2 | 28,2 |
On peut constater que nos efforts ont été utiles : dans les deux approches, nous avons pu diminuer la consommation énergétique de notre programme. Cependant, la version dans laquelle nous avons réduit le nombre de threads s'exécute trop lentement pour pouvoir battre la version parallèle. On consomme effectivement moins de puissance, mais pendant beaucoup plus longtemps qu'avec la version parallèle. La meilleure solution pour ce programme est donc clairement la parallélisation. C'est d'ailleurs généralement le cas si le programme peut se paralléliser facilement, mais ce n'est pas toujours facile de paralléliser correctement son programme.
IV-E. Téléchargements▲
Vous pouvez récupérer les programmes utilisés pour cette expérimentation dans cette archive.
V. Conclusion▲
Les études sur la consommation énergétique d'un programme sont très récentes et il n'existe aujourd'hui encore que peu de techniques pour limiter la consommation énergétique. Cependant, au vu de l'évolution du matériel, il est probable que de nombreuses avancées voient bientôt le jour, nous permettant de limiter l'énergie consommée par nos ordinateurs. En attendant, on a vu qu'il est aussi possible d'agir sur son code en l'optimisant et en réduisant l'utilisation des ressources matérielles lorsque cela n'impacte pas le temps d'exécution.
VI. Remerciements▲
Merci à Jamel Tayeb (Intel), Smaïl Niar (Université de Valenciennes) et Benoit Pradelle (Université de Saint-Quentin-en-Yvelines) pour leur aide et leur support durant la réalisation de ce document.
Merci à ClaudeLELOUP pour sa relecture orthographique.